Clustering of Archaeological Entities - An Information Theory Based Approach
Remuera, Auckland, New Zealand.
1999
Contents
| New on this page:
Updated BASIC program to perform clustering as per this paper - now with input and output files. LINK |
Examples
Information theory provides a powerful method of analysing and clustering archaeological data that exists in categorised form. The approach can be used to cluster entities hierarchically and select optimal levels of clustering based internally on relative information or on having the maximum interaction with archaeological provenance. Three examples illustrate some of a variety of applications of the method looking at data from the Riverton adze manufactory in Southland, New Zealand, obsidian characterisation data from the southern Admiralty Islands in the western Pacific and shell fishhook points from northern New Zealand. |
The normative behaviour which forms a large part of the culture of a society can be considered as information. The information may be a snapshot of a society or some aspect of it, or at another level it may describe the way in which a society perpetuates itself, by its internal transmission of information. Archaeological information can only rarely provide the snapshot view of even an aspect of a society. Rather archaeological information often expresses human behaviour in an indirect manner and its range can show only a small part of the information which existed within a culture.
Archaeologists reconstruct behaviour from archaeological information by seeking order in information which can be linked to theories of how people or societies behave. An output from an investigation which contains much detail of location, categorisation, enumeration within categories is in current terminology one which would be called data rich. The concept that a report contains a great deal of information aligns happily with this. In contrast an investigation output which is predominantly interpretation is not data rich. For instance a site investigation might be able to be reduced to a one sentence summary assigning its early occupation to a particular cultural phase and a later occupation to another. Clearly in such a case interpretive work has been done to produce a generalisation with interpretive categories, occupations and cultural phases. Being a generalisation it can be considered as having little information in the sense of the original site information. An investigator might well be offended if told that the output of the work was such. It is not necessarily a judgement on the generalisation process but a matter of fact in terms of measurable information. Reduction of data has taken place. The new output could be said to have information in an interpreted form which was entirely absent in the original data.
An analogy is to consider the word "cat" written using three letters and a digitalised scan of the sound waveform of someone saying the word cat. The written word is a much more efficient and condensed version of the information in the waveform. It can be seen as interpreted information. However what might be lost in the transition from the waveform to a single written word is for instance that cat was spoken with a Welsh accent. Hence some information may well be lost in moving to an interpreted form of information.
Much archaeological information is produced in categorised form. Theory, often implicit rather than explicit determines the attributes archaeologists consider worthy of record, as well as the categories used to classify the attributes and the way the relationships between the categorised attributes are investigated.
Often the aim of a generalisation of the information is to expose order and relationships which exist between categorised data and explain these in cultural terms. In a situation where the data are voluminous identifying order of relationships is not convincingly achieved by inspection An investigator is presented with the problem of producing efficient generalisations of the data.
The following presents a technique from information theory which explicitly uses information theory as a measure of success in generalising categorised data.
If a unit can be categorised un-ambiguously into say one of eight categories then it is possible to signal the category into which the unit belongs using yes / no signals. Table 1 shows this being done for categories lettered A to H:
Table 1
| Category | Frequency P |
Signal Number | ||
| 1 | 2 | 3 | ||
| A | 0.125 | Yes | Yes | Yes |
| B | 0.125 | No | ||
| C | 0.125 | No | Yes | |
| D | 0.125 | No | ||
| E | 0.125 | No | Yes | Yes |
| F | 0.125 | No | ||
| G | 0.125 | No | Yes | |
| H | 0.125 | No | ||
| Total | 1.000 | |||
A yes / no signal is normally called a bit and in this case the number of bits of
signals to clearly signal a category can be calculated as ![]() This number of bits - in
this case 3 - can be called the information capacity of the categorisation. Note that we
have indicated that each category has the same frequency - each is as probable as another
- they are equi-probable. Consider now if we know that all categories are not
equi-probable, so that before a category is signalled we know that some categories are
more frequent than other categories. Because the message in a signal from this system is
to an extent predictable in a statistical way the information capacity of the system is
lower than the first case considered.
This number of bits - in
this case 3 - can be called the information capacity of the categorisation. Note that we
have indicated that each category has the same frequency - each is as probable as another
- they are equi-probable. Consider now if we know that all categories are not
equi-probable, so that before a category is signalled we know that some categories are
more frequent than other categories. Because the message in a signal from this system is
to an extent predictable in a statistical way the information capacity of the system is
lower than the first case considered.
Taking a series of categories in rank order shown in Table 2 it can be seen that the higher frequency categories can be signalled with less bits.
Table 2
| Category | Frequency P |
Number of Bits to signal | Signal Number | ||
| 1 | 2 | 3 | |||
| U | 0.500 | 1 | Yes | - | - |
| V | 0.250 | 2 | No | Yes | - |
| W | 0.125 | 3 | No | Yes | |
| X | 0.125 | 3 | No | ||
| Total | 1.000 | ||||
The number of bits in any row in Table 2 can be calculated as: ![]()
The weighted average number of bits for this system of categorisation is:
![]() ...................................................
(1)
...................................................
(1)
In this case H = 1.75
In contrast the information capacity of a four way categorisation of equal category frequency would be 2.0 Hence having equi-probable categories gave a higher information capacity.
In the previous example for an eight way categorisation the number of bits used overall was 3, and the weighted average number of bits was the same at 3.
In fact the formula given in (1) has more general application to category frequencies
than has been shown here. It is not limited to values of P (frequencies) which are
inverses of 2 raised to integer powers ![]() as in Tables 1 and 2 above. The formula is a
fundamental one known as Shannon's Information H and has wide application in science,
being used for example in biological science as a measure of diversity and is finding
similar application in archaeology (Leach 1978, Rice 1981, Conkey 1981).
as in Tables 1 and 2 above. The formula is a
fundamental one known as Shannon's Information H and has wide application in science,
being used for example in biological science as a measure of diversity and is finding
similar application in archaeology (Leach 1978, Rice 1981, Conkey 1981).
Consider the effect of adding an extra bit of information to a categorisation. This in effect duplicates the categorisation and can be represented by a two way table (Table 3).
Table 3
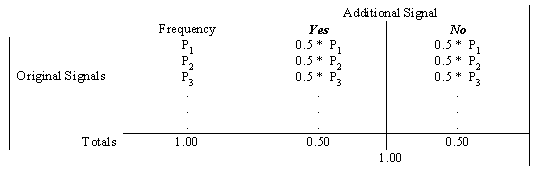
If ![]() was the information capacity of the original category system, an increase to
was the information capacity of the original category system, an increase to ![]() would
be expected.
would
be expected.
This can be demonstrated:
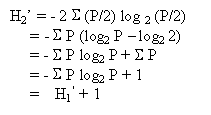
where ![]() is the original information capacity.
is the original information capacity.
If the additional signal was not a simple bit but an additional categorisation (Table 4):
Table 4

The two categorisation systems have information:
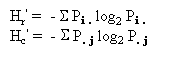
The total system has information:
![]() ............................................... (2)
............................................... (2)
If ![]() then it can be readily shown that:
then it can be readily shown that: ![]()
If the second categorisation is not independent of the first then we would
expect the information capacity of the system to be degraded from the maximum given by the
sum of ![]()
Independence implies:
![]() ..................................................................(3)
..................................................................(3)
It can be demonstrated algebraically that for fixed marginal totals and if independence initially obtains, any transfer of frequency between any cells of the nature:
![]()
lowers the value of ![]() calculated by (2). This demonstrates that the
condition (3) is at least a local optimum for
calculated by (2). This demonstrates that the
condition (3) is at least a local optimum for ![]()
It is possible then to use the departure from the maximum information:
![]() .......................................................... (4)
.......................................................... (4)
as a measure of the degree of dependence between two systems of categorisation. This can be one as a measure of relative information:
![]() ......................................................... (5)
......................................................... (5)
Low values imply independence and high values dependence between the two categorisation systems. While the minimum value for R is zero, the maximum value is less than one and usually much closer to zero than one.
It is desirable to use natural base logarithms (ln) rather than base 2 logs because the former are more convenient for calculation than the latter and secondly there is a statistical test which can be directly applied when natural logarithms are used.
If in a table such a Table 4, actual counts are substituted for proportions, i.e.
![]() then substituting sample estimates for cell
probabilities and using natural logs:
then substituting sample estimates for cell
probabilities and using natural logs:
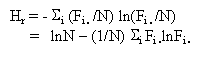 .................................... (6)
.................................... (6)
Similarly:
![]() ..................................... (7)
..................................... (7)
and:
![]() ..................................(8)
..................................(8)
Then the departure from maximum information is similarly to (4):
![]() ................................ (9)
................................ (9)
and the relative information is:
![]() ............................ (10)
............................ (10)
Kullbach et. al. (1962) show that when independence applies then,
K = 2NJ ............................. (11)
is distributed asymptotically as Chi-squared with degrees of freedom V = (r-1)(c-1) where r and c are the number of rows and columns respectively. This allows the value of (11) above to be used as a contingency table test of the null hypothesis of independence. This test is an alternative to the well known contingency table application of Chi-squared. The test is no more robust than the Chi-squared test and low expected values are to be avoided with this test in the same manner as is well known for the Chi-squared contingency table test.
Consider a situation where a table had been condensed by at random combing rows and or columns from one with :

Let:
![]() ......................................................... (12)
......................................................... (12)
(NB D J is negative), then from the additive
property of Chi-squared -2N D J has Chi-squared distribution
with degrees of freedom: ![]() In a situation where condensing the table has
combined rows or columns which are correlated the value of -2N D
J could be significantly low when tested against the Chi-squared distribution. In cases
where combinations of rows or columns have perfect correlation D
J will be zero. Values of D J close to zero make it likely that
In a situation where condensing the table has
combined rows or columns which are correlated the value of -2N D
J could be significantly low when tested against the Chi-squared distribution. In cases
where combinations of rows or columns have perfect correlation D
J will be zero. Values of D J close to zero make it likely that
![]() will
be greater than
will
be greater than ![]()
This leads directly to a method of clustering categorised data. When clustering say rows, all possible pairs of rows can be searched for the pair which maximises the absolute value of D J, but note in this case because the pair are selected for this criterion the statistical test on D J no longer applies. Clustering can continue until all the set is joined, or until the maximum value of R is passed. In the latter case having such a positive indication as to the point at which further clustering is no longer warranted gives the procedure an advantage over many other clustering methods where this is often a problem.
To plot a hierarchy of clustering the value of D J can be used as a measure of distance between entities joined. An example is given with the program below.
A BASIC program to undertake clustering as above is available free at LINK.
In many cases the archaeologist is seeking to establish or maximise dependence between two categorisation (classification) systems. The normal consideration of the null hypothesis of independence is sufficient tool in many cases but considering dependence from an information point of view has an advantage where the question of redundancy in the classification system is considered. If one classification system is condensed and the relative information R increases, showing the classifications are now more related than before then the information lost from the total in condensing can be regarded as of little importance. In other words the information lost condensing one classification had no predictive value in respect of the other classification.
What is being manipulated now, is information measured on a ratio scale (Thomas 1976:27), that is a much higher level than the nominal scale that the categorised data started upon. The process of condensing is best illustrated by way of examples as below.
While the method was derived above for use with categorised data, there does not seem to be any great inhibition to using the clustering method with presence / absence data, scoring present as 1, absent as zero. Clusters are still sum scores not re-scored to present or absent. Of course the contingency table test is not applicable with this sort of data.
Summary:
| For a two way cross classification table a high R value implies one classification has predictive value for the other - they are associated. |
| If in condensing a table one amalgamates rows (or columns) on the basis of a low D J value when they are looked at pairwise, then this has arisen because there is a close correlation or association between the rows or columns combined. The condensed table is a more concise summary of the information in the original table, though usually some information will be lost. Association between rows (or between columns) is information which can be summarised efficiently by amalgamating the rows (or columns as the case may be). Amalgamation does not imply there is no information value in closely associated rows (or columns), quite the reverse. It is the pairing in an amalgamation that is the piece of information which summarises the efficient reduction of the overall information in the remaining table. Having a low D J will maximise the value of R in the condensed table. |
| Monitoring the value of R is a way of checking that progressive amalgamations are achieving greater concision without discarding too much information. |
| Condensing a table as proposed here reduces the amount of raw information. However information is summarised in a form which is more valuable to an archaeologist as it leads to higher level constructs in interpreted information than the mere raw data. |
Examples
Leach and Leach (1980) present data on flake material recovered from an adze manufacturing site at Riverton in southern New Zealand adjacent to a quarry source of the rock. The flake and flaked material was localised by excavated squares and classifies into categories
Class A: primary reduction flakes,
Class B: trimming flakes with platforms showing signs of previous trimming,
Class C: broken and small flakes,
Class D: preforms and tools.
Table 5 is a condensation of their table showing only squares where more than 100 classified objects were found.
Table 5 - Flake Material, category against Area at Riverton
Area |
Category | Total | |||
| A | B | C | D | ||
| 1 | 66 | 112 | 107 | 9 | 294 |
| 2 | 111 | 135 | 75 | 9 | 330 |
| 3 | 172 | 213 | 154 | 18 | 557 |
| 4 | 601 | 763 | 375 | 104 | 1843 |
| 5 | 1477 | 831 | 1493 | 61 | 3862 |
| 6 | 18 | 25 | 60 | 4 | 107 |
| 7 | 30 | 290 | 171 | 17 | 508 |
| 8 | 49 | 324 | 320 | 14 | 707 |
| 9 | 93 | 64 | 11 | 6 | 174 |
| 10 | 141 | 127 | 56 | 32 | 356 |
| 11 | 156 | 293 | 140 | 46 | 635 |
| Total | 2914 | 3177 | 2962 | 320 | 9373 |
Calculating the relative information
![]() = ln9373 - (294 ln294 + 330 ln330 + 557
ln557 + ... + 635 ln635) / 9373
= ln9373 - (294 ln294 + 330 ln330 + 557
ln557 + ... + 635 ln635) / 9373
= 91.356 - 68251 / 9373
= 1.8639
![]() = ln 9373 - (2914 ln2914 + ... + 320 ln320) /
9373
= ln 9373 - (2914 ln2914 + ... + 320 ln320) /
9373
= 1.2093
![]() = ln 9373 - (66 ln66 + 111 ln111 + ... 112 ln112
+ ... + 46 ln46) / 9373
= ln 9373 - (66 ln66 + 111 ln111 + ... 112 ln112
+ ... + 46 ln46) / 9373
= 3.0056
J = 1.8639 + 1.2093 - 3.0056
= 0.0676
R = 0.0676 / (1.8639 + 1.2093)
= 0.220
Looking at the test for association:
K = 2* 9373 * 0.220 = 1267 with (11-1)(4-1) = 30 degrees of freedom. This is highly significant indicating the occurrence of classes in squares is not a simple random process. The question can be asked; "which classes if any associate?" There are six different pairings of classes which can be tried and a new value of R calculated for each reduced table produced. If classes A and B are combined the first column is replaced by 66 + 122, 111 + 135 etc. This clustering can be represented as (AB)CD. The reduced table with the highest value of R indicates a clustering where the two combined classes associate most closely, leafing more real information in the table, or in other words representing the data in a more efficient form with least loss of information. The two classes combined contribute the least to the information in the table because they associate closely. Table 6 gives the results of this analysis
Table 6 - Relative information R, for different combinations of categories of flake material.classes
| Combination | R | |
| 3 Groups | (AB)CD | 0.0118 |
| (AC)BD | 0.0147 | |
| (AD)BC | 0.0198 | |
| (BC)AD | 0.0153 | |
| (BD)AC | 0.0217* | |
| (CD)AB | 0.0185 | |
| 2 Groups | (BD)(AC) | 0.0141* |
| (BDC)A | 0.0134 | |
| (BDA)C | 0.0096 |
* Maximum
As can be seen the combination of B and D produced the highest result for R but not as high as the value for the full table. If as a further clustering pass the number of groups is reduced to two, the values of R are shown in the second part of Table 6. Again the R values are lower with (BD)(AC) which has the highest R for two groups.
The result suggests the class of trimming flakes and the class of tools and preforms associate spatially in the site. The site can be interpreted as having primary reduction areas and finishing areas for tool manufacturing. This conclusion was also advanced by Leach and Leach who tabulated the variation in the ratios of classes A to B and interpreted the variability as evidence of such patterning. It is suggested the approach here is a more elegant one.
Looking at the condensation of the data:
Data state |
Measured information content | Interpreted information |
| Original data - Table 5 | High | Nil |
| Condensed table - reduced to two groups (BD) (AC) |
|
Correlation established |
| Derived information: "site ... having primary reduction areas and finishing areas for tool manufacturing" | Nil | Interpretation established |
Ambrose, et. al. carried out proton induced X-ray emission and gamma ray emission measurements reflecting element concentrations in 338 obsidian sources (geological exposures, prehistoric quarries and prehistoric occupations) in the southern Admiralty Islands. For each item 22 variables were measures (counts on X-ray energy windows) Using these 22 variables the 338 items were clustered together using Euclidean distances as a measure of association between pieces. The authors chose to settle on 9 clusters "because a maximum amount of archaeological information appears to be present consistent with a minimum number of groups." Figure 1 shows their groups and the source categories wherein the archaeological information is seen.
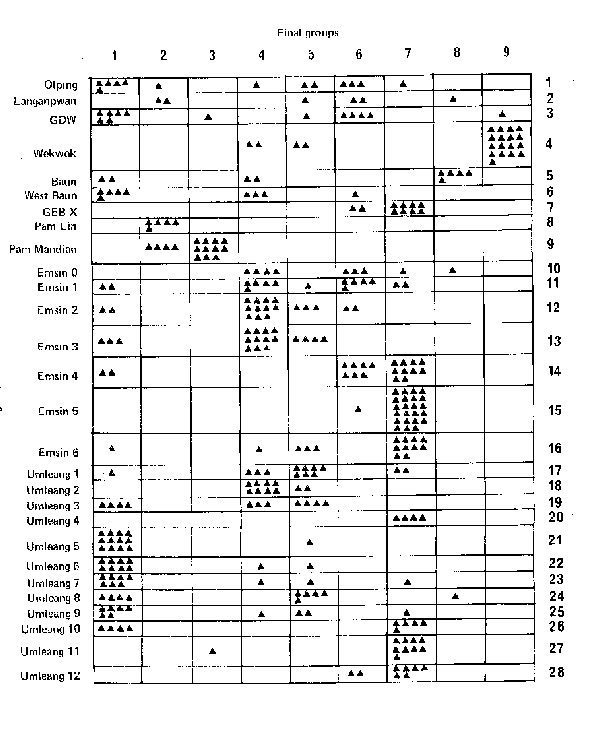
Figure 1 - From Ambrose et. al.
The authors state that if the clusters were to be condensed to 8 groups then groups 1 and 4 would have been combined and if reduced to 7 groups then groups 6 and 7 would have been combined. This would produce the most efficient clusters measured by consideration of Euclidean distances from individual items to the cluster means, based on the counts as data. While there may have been some re-allocation in the condensation process the authors have not published data on this. By assuming this was absent or of minor importance the relative information of the three alternative clusterings at k = 7, 8 and 9 can be tested. Table 7 shows the components of the calculations.
Table 7 - Relative information R in southern Admiralty Islands obsidian sourcing.
| K | R | |||
| 7 | 1.4768 | 3.2590 | 3.8577 | 0.185 |
| 8 | 1.6785 | 3.2590 | 3.9591 | 0.198 |
| 9 | 1.9447 | 3.2590 | 4.0925 | 0.214* |
* Maximum
As can be seen K = 9 has the highest relative information, as the authors believed. It should be noted that the quoted statement of the authors regarding the maximum amount of archaeological information does not refer to the condensed table where K = 9 In that case the amount of information is much reduced from the original data matrix but refers instead to the interpreted archaeological information.
This example demonstrates the potential to use of information measurement to look at the interaction of clustering and provenance to enhance selection of a level of clustering which has the most useful association with provenance.
Law (1984) attempts to recognise types within a relatively homogeneous population of point halves of two piece fishhooks. The shapes of 115 points defined by seven linear dimensions and a further two discrete parameters enumerating attachment notch numbers which were accepted as if they were continuous. Using these nine dimensions the items were clustered together using a K-Means multivariant technique. Clusterings with a number of clusters (K) in the range 2 to 5 were considered. A second study on these and other broken points yielded a classification of the base ends which were not definable by the linear dimensions. This was a hierarchical classification based on the inferred attachment method with categories A, Ba, BbA and BbB where the lettering implies the hierarchy with A / B the most fundamental division.
It was expected this latter classification would be related to the first as the base attachment will relate to the point shape and the base notching numbers used in the multivariate clustering relate to the base form categories. The separate base form classification was seen as a useful exercise as it allows the classification of broken points, which are more frequent than whole points in archaeological sites (unlike the museum collections studied where whole points had clearly been selected). The multivariate study allows more attributes of the points to be included. As the clustering process allows re-allocation of points between clusters as the number is reduced separate cross classification tables are needed for different values of K. The tables are not given here. There are 12 of them representing the product of four different levels of multivariate clustering (K= 2 to 5) and three different levels of hierarchy in the base classification (A / B, A / Ba / Bb and A / Ba / BbA / BbB).
Values of the relative information R can be calculated for each of the tables. Table 8 shows these values.
Table 8 - Relative information R for different combinations of types of shape and base style applied to Maori shell fishhook points.
Number of Shape Types (K) |
|||||
| Number of Base Types | 2 | 3 | 4 | 5 | |
| 2 | 0.038 | 0.029 | 0.037 | 0.020 | |
| 3 | 0.040 | 0.037 | 0.057 | 0.036 | |
| 4 | 0.049 | 0.057 | 0.066* | 0.051 | |
* Maximum
At K = 4 shape clusters and the four fold base type division the highest value of R occurs. The two typologies are therefore supportive of each other at this level of partition, even though a one to one equivalence of types does not occur. It is of particular interest then to note that prior to this analysis, partition at K = 4 had been selected as the most parsimonious of the information internal to the multivariate clustering process.
The intuitive concept of information content is often called upon by archaeologists. This paper has shown the measurable information content of the categorised data archaeologists commonly collect can be explicitly used in handling that data. The data existing in nominal scales in categorised data is often the least manipulable form of data statistically. Using information concepts allows use of interval scale statistics, that is a transition to the highest form of measurement scales.
Note
This paper was originally written in the mid 1980's and has not ever been submitted for formal publication. The references reflect the date of writing. If readers are aware of other archaeological publications using Information H or using information theory based clustering, I would be interested to hear of them and happy to update the references.
Ambrose, W R, J. R Bird and P Duerden, 1981: "The impermanence of obsidian sources in Melanesia." in F Leach and J Davidson, Eds. Archaeological studies of Pacific stone sources, British Archaeological Reports, International Series, No 104.
Conkey, M W, 1961: "The identification of prehistoric hunter-gatherer aggregation sites: The case of Altamira." Current Anthropology 21:609-20.
Ku, H H, and S Kullback, 1968: "Interaction in multidimensional contingency tables: an information theoretic approach." Journal of Research of the National Bureau of Standards B72:158.
Kullback, S, M Kupperman and H H Ku, 1962: "Tests for contingency tables and Markov chains." Technometrics 4:573.
Law, R G, 1983: "Maori shell fishhook points from northern New Zealand." New Zealand Journal of Archaeology 6:5-21.
Leach, B F, 1978: "Four centuries of community interaction and trade in Cook Strait, New Zealand." Mankind 11:391-405.
Leach H M, and B F Leach, 1980: "The Riverton site, an archaic adze manufactory in western Southland, New Zealand." New Zealand Journal of Archaeology 2:99-140.
Rice, P M, 1981 "Evolution of specialised potter production: a trial model." Current Anthropology 22:219-227.
Thomas, D H, 1976: Figuring Anthropology. Holt, Rheinhart and Winston, New York.
- end -
July 02, 2001